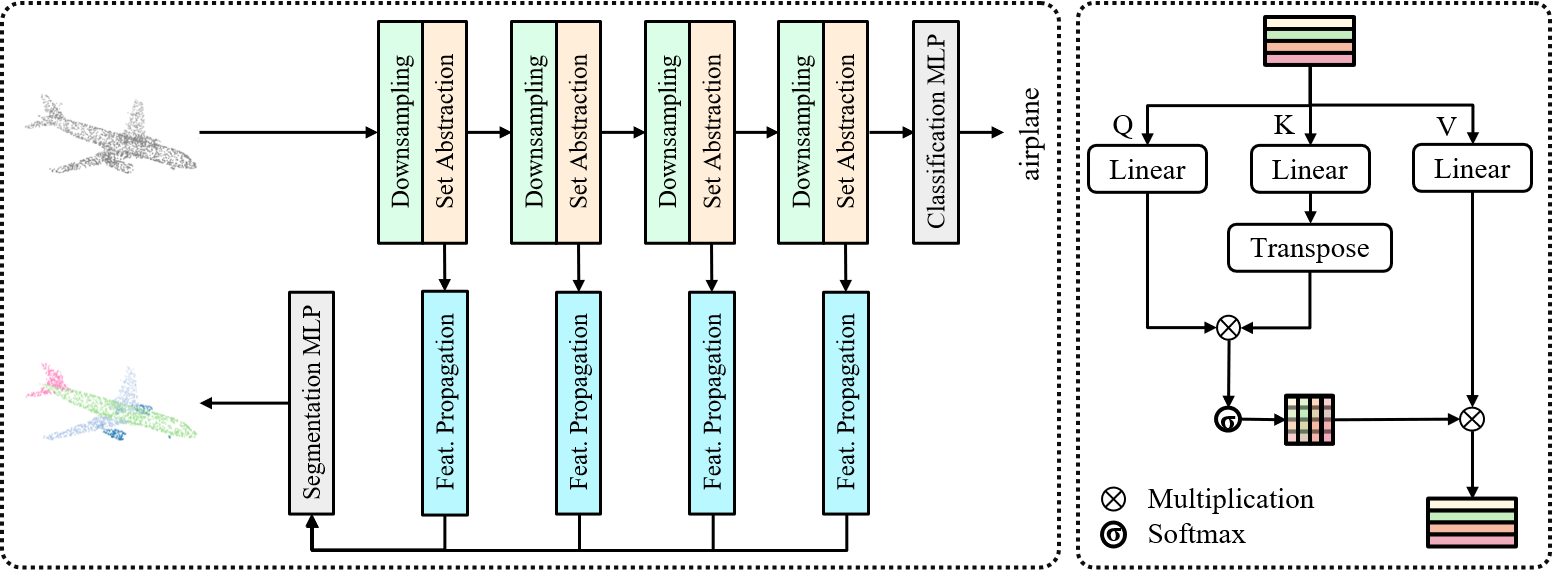
Transformer architectures have been extensively validated for modeling structural
relationships in natural language and vision tasks, yet positional encoding in 3D point
cloud learning is often overlooked or oversimplified. In this paper, we systematically
review and analyze existing point cloud positional encoding strategies, revealing their
limitations in scale awareness and local geometric capture. Motivated by the observation
that no single encoding can simultaneously capture global, intermediate, and local spatial
dependencies, we propose a Triadic positional encoding framework comprising:
Multi-Scale Positional Encoding, which leverages coarse-to-fine hierarchical
attention combined with delta-coordinate aggregation to capture global and intermediate
contextual cues; Local Geometric Encoding, which focuses on extracting fine-level
local structural patterns; Relative Positional Encoding, which generates enriched
relative position embeddings by applying expert-level gating and soft assignment to each
point-pair’s relative coordinates, and then aggregating the corresponding codebook vectors
via weighted combination. We integrate these three encoding modules into a hierarchical
point cloud backbone and evaluate our approach on multiple challenging 3D benchmarks,
including ModelNet40, ScanObjectNN, ShapeNetPart, S3DIS and ScanNet v2. Experimental results
demonstrate consistent and significant improvements in semantic segmentation, part
segmentation, and object classification tasks, validating the critical role of carefully
designed positional encodings for 3D perception.